- 1
以前のエントリーControlNet を使ってざっくり手描きした絵から期待する画像をつくる を書いたのですが、Diffusers ライブラリを使えば、Web UIではなく、コマンドラインから python コードを実行する形で、 画像を作り出すことができることがわかりました。 その結果を備忘録として書き残します。

前回のエントリーで Hugging Face の Diffusers ライブラリを使用して テキストから画像を生成しました。今回はその続きで、それを Bottle を使ってWebサーバにしました。
venv 環境は前回作成した diffuers 環境をそのまま引き継いでいる点に注意してください。(OS は M1 macOS ではなく Linux(Ubuntu) を使います。)

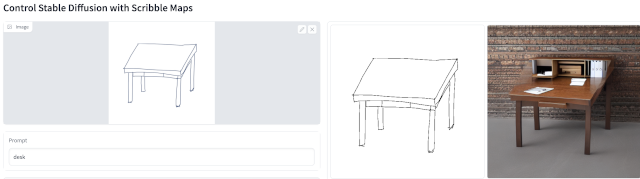
https://github.com/lllyasviel/ControlNet を使ってみました。 ControlNet はいくつかの機能があるのですが、その中の手描き画像+プロンプトから画像を生成するものを試しました。

ChatGPTのAPIを試そうと思って OpenAI アカウント作成したのですが、画像生成がおもしろそうと思ってそちらを試しました。 これが「A sheltie is running around the field」というテキスト(プロンプト)から生成した画像です。(OpenAI の Create Image APIを使用)

- 1