- 1
- 2


torch_dtype=torch.float16 指定を外すとどうなるか試しました。
» Read Moreそこそこに速いシリコンマックで ELYZA-japanese-Llama-2-7b-fast-instruct を使って クライアントからテキストを投げると JSON文字列 を返すサーバをつくります。
» Read MoreLarge Language Model をローカルで動かす時代が到来するらしい。
Reddit には LocalLLaMA というサブレディットがあり、かなり盛り上がっている。 そこでは シリコンマックを使っているひとが結構いる。 Meta の 商用利用も可能な Llama 2 がオープンソースで提供された結果、 その派生プロジェクトがいろいろ存在している。 そのなかには、低スペックの シリコンマックでも LLM を実行できるものがある。 Pytorch もMetal 対応していて、 おそらくは、Pytorch 依存の LLM モデルについては、Linux + CUDA と同じ手順で動かせるのではないかと思う。
Pytorch を使う方法を 手元の M1 Macbook Air 8GB で試したが残念ながら作動しなかった。 たぶんメモリが足りないのだと思う。 十分メモリがあれば動くのではないかと思うが定かではない。
それでも Llama.cppと軽量化されたモデルを使うことで M1 Macbook Air 8GB でも作動させることができた。
このエントリーでは、Linux + CUDA で、 Llama 2 をベースに商用利用可能な日本語LLM ELYZA を試します。
» Read More
支給されたデータのうち特定の列だけを抜き出して使いたい、という場合に pandas を使ったのでその備忘録です。
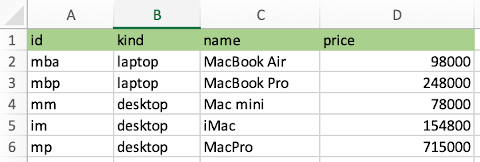
こんなエクセルデータがあったとして、これを pandas で処理する。
» Read MoreGoogle の Cloud Vision APIの機能のひとつにOCRがあり これを業務で使う機会がありました。 実際に使ってみると、対象が印刷物をスキャンした画像データだったなど条件がよかったのだとは思いますが ほぼOCR処理として100%に近い形でテキストに変換されました。 とはいえ、100%ではないので、そこは人間が一度はすべて確認する必要がありますし、 そもそもOCRで読みとったテキストをこちらが使用したい単位に整理する処理については 当然OCRの守備範囲外になります。 そのため、その部分のコードを書くのが相当に大変でした。
もし人間が目視&手作業としてテキスト入力すれば、その整理部分も含めて人間が処理することになる。 それがアウトソーシングとしてページ単価いくらで予算の範囲で収まるのであれば、 どうなんだろう。 自分ががんばって書いたコード部分は結局たいした価値があるのだろうか……という微妙な仕事になってしまった。
» Read More
画像を分類が PyTorch + fastai で簡単にできることがわかったのでその覚え書きです。
PyTorch + fastai だけでなく、 Lobe( https://www.lobe.ai/ ) や Google Vision AI にしてもそうですが、 無料で画像分類を試すことができます。 もう、この程度のことでは、誰も驚かない時代になった。
» Read Morepandas が Excel + VBA の代わりとして使える可能性があるらしい。 Jupyter Notebook と併用すれば、インタラクティブに処理結果を確認しつつデータ操作できるので、確かにこれは便利。
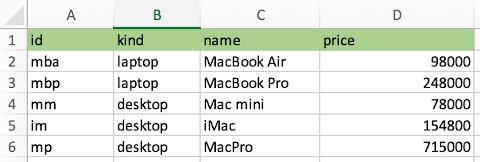
こんなエクセルデータがあったとして、これを pandas で操作していく覚え書き。
» Read More- 1
- 2