ノイズから画像を創り出す機械学習 DDIM
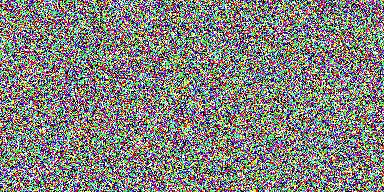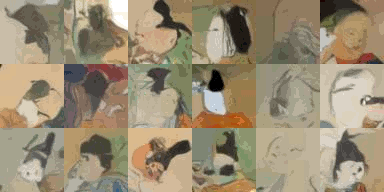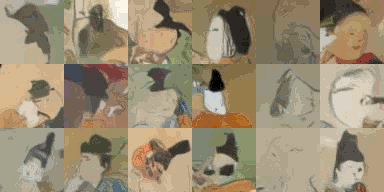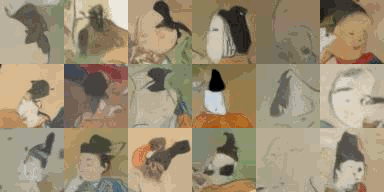
Denoising Diffusion Implicit Models を試した。 このページではデータセットは oxford_flowers102 を使用していますが、それに代えて 顔コレ および ポケモン データセット を使ってトレーニングしてみました。
参考にした Keras のこのページのコード から変更した点を書き残します。
Seed の固定(毎回、同じノイズを使う)と訓練進捗状況確認用画像の書き出し
DiffusionModel クラスの plot_images 関数で epoch 毎に進捗状況を画像として出力しています。 この部分で、毎回ランダムなノイズを生成してそこから画像を生成しますが、 進捗状況がわかりやすいようにこのときのノイズを固定します。
noise_generator モジュール(noise_generator.py)を作成します。
import os
import json
import tensorflow as tf
import numpy as np
class NoiseGenerator:
def __init__(self, image_size, num_rows, num_cols):
self.image_size = image_size
self.num_rows = num_rows
self.num_cols = num_cols
self.json_file = '_'.join(['noise', str(image_size), str(num_rows), str(num_cols)]) + '.json'
@staticmethod
def save(json_file, noise):
noise_json = json.dumps(noise.numpy().tolist())
with open(json_file, 'w') as f:
json.dump(noise_json, f)
@staticmethod
def load(json_file):
with open(json_file, 'r') as f:
noise_json = json.loads(json.load(f))
return tf.convert_to_tensor(value=noise_json, dtype=tf.float32)
def generate(self):
if not os.path.exists(self.json_file):
num_images = self.num_rows * self.num_cols
noise = tf.random.normal(shape=(num_images, self.image_size, self.image_size, 3))
self.save(self.json_file, noise)
return noise
else:
return self.load(self.json_file)
image_size と num_rows, num_cols がパラメータなので、 それを使って NoiseGenerator を初期化します。 あとは、generate() を使ってノイズを生成させるのですが、 このとき、同じパラメータを使っている場合は、 以前生成したノイズをファイルに保存しておき、それを再利用する、 というコードです。
これを使って該当メソッド(plot_images)を以下のように書きかえます。
import noise_generator
...
class DiffusionModel(keras.Model):
....
def generate_for_plot_images(self, num_rows, num_cols, diffusion_steps):
noise = noise_generator.NoiseGenerator(image_size, num_rows, num_cols)
generated_images = self.reverse_diffusion(noise, diffusion_steps)
return self.denormalize(generated_images)
def plot_images(self, epoch=None, logs=None, num_rows=3, num_cols=6):
#generated_images = self.generate(num_images=num_rows * num_cols, diffusion_steps=plot_diffusion_steps)
generated_images = self.generate_for_plot_images(
num_rows=num_rows,
nul_cols=num_cols,
diffusion_steps=plot_diffusion_steps)
self.export_plot_images(epoch, num_rows, num_cols, generated_images)
また、export_plot_images メソッドを追加して、generated_images を pyplot で描画している部分を PIL を使って画像としてファイルに出力するように変更しました。
from PIL import Image
...
@staticmethod
def export_plot_images(epoch, num_rows, num_cols, generated_images):
export_dir = 'images_{:04d}'.format(epoch)
os.makedirs(export_dir, exist_ok=True)
for row in range(num_rows):
for col in range(num_cols):
index = row * num_cols + col
numpy_image_array = generated_images[index]
pil_image = Image.fromarray(np.uint8( (numpy_image_array * 255.0) )).convert('RGB')
jpg_filename = str(index).zfill(2) + '.jpg'
jpg_file_path = os.path.join(export_dir, jpg_filename)
pil_image.save(jpg_file_path)
訓練を途中から再開できるようにする
元のコードでは、訓練終了時に checkpoint をファイルに保存していました。 これをロードできるようにします。 これは訓練再開(前回訓練した重みをロードしてから訓練開始)したり、 訓練済みのモデルを使って推測(ノイズからの画像生成)する場合に使います。
checkpoint をロードするコード:
# Loads the weights of previous
checkpoint_dir = os.path.dirname(checkpoint_path)
if os.path.exists(checkpoint_dir):
latest = tf.train.latest_checkpoint(checkpoint_dir)
model.load_weights(latest)
checkpoint が存在していたら、その訓練済みの重みをロード。
see also: https://www.tensorflow.org/tutorials/keras/save_and_load
これを model.fit する前に書いておきます。
Data pipeline の変更
Oxford Flowers 102 の代わりに 顔コレを使うので、データセットをロードする部分を変更します。
顔コレデータのダウンロードは、こちらのプロジェクト https://github.com/rois-codh/kaokore を利用します。 このページの説明の通りですが、download.py 使って顔コレデータを入手します。
$ git clone https://github.com/rois-codh/kaokore.git
$ cd kaokore/
$ python3 download.py --dataset_version 1.3
実行すると ./kaokore/images_256/ 以下に 9683 件の顔画像がダウンロードされます。
kaokore モジュールを用意します。( kaokore..py )
from glob import glob
import tensorflow as tf
class KaokoreDataset:
def __init__(self, image_path, image_size, dataset_repetitions, batch_size):
self.image_path = image_path
self.image_size = image_size
self.dataset_repetitions = dataset_repetitions
self.batch_size = batch_size
def preprocess_image(self, image_path):
image_file = tf.io.read_file(image_path)
image_tensor = tf.image.decode_jpeg(image_file, channels=3)
image_tensor = tf.image.resize(image_tensor, size=[self.image_size, self.image_size], antialias=True)
image_tensor = tf.cast(image_tensor, tf.float32) / 255.0
return image_tensor
def prepare_dataset(self, images):
return (
tf.data.Dataset.from_tensor_slices(images)
.map(self.preprocess_image, num_parallel_calls=tf.data.AUTOTUNE)
.cache()
.repeat(self.dataset_repetitions)
.shuffle(10 * self.batch_size)
.batch(self.batch_size, drop_remainder=True)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
def load(self):
images = glob(self.image_path)
train_dataset = self.prepare_dataset(images[0:7500])
val_dataset = self.prepare_dataset(images[7500:])
return (train_dataset, val_dataset)
以下のようにして使います。
import kaokore
...
dataset_repetitions = 5
image_size = 64
batch_size = 64
...
image_path = 'kaokore/images_256/*.jpg'
train_images, val_images = kaokore.KaokoreDataset(image_path, image_size, dataset_repetitions, batch_size).load()
変更点は(たぶん)以上です。
訓練済みのモデルとノイズから画像を生成
十分訓練できたら、それを使って顔画像を生成します。
訓練用のコードの最後の部分に以下のコードを追記します。
なお 当然ですが、 model.fit() は削除するなりコメントアウトするなりして訓練が実行されないようにします。
# Loads the weights
checkpoint_dir = os.path.dirname(checkpoint_path)
latest = tf.train.latest_checkpoint(checkpoint_dir)
model.load_weights(latest)
# Generate face images
num_images=3
generated_images = model.generate(
num_images= num_images,
diffusion_steps=plot_diffusion_steps)
for index in range(num_images):
numpy_image_array = generated_images[index]
pil_image = Image.fromarray(np.uint8( (numpy_image_array * 255.0) )).convert('RGB')
jpg_filename = str(index).zfill(3) + '.jpg'
pil_image.save(jpg_filename)



plot_diffusion_steps の値を十分大きく(たとえば 50以上)にすると より精細な画像ができるかもしれません。
ポケモンデータセットを使う
819 枚のポケモン画像 があったので、顔コレに代えて訓練してみました。 こちら https://github.com/kvpratama/gan/ の pokemon/data/pokemo/ から画像を入手できます。
結果はこれです。
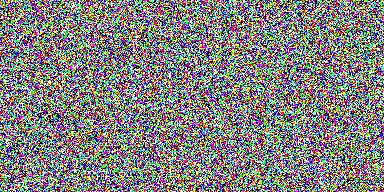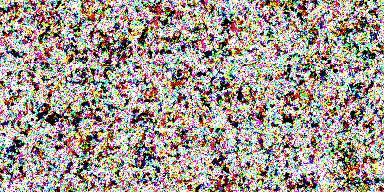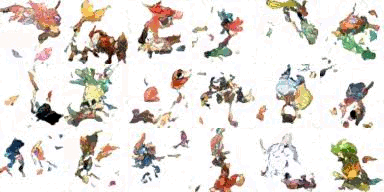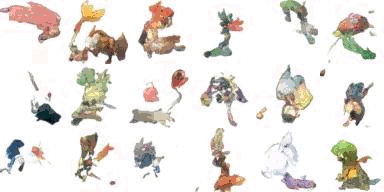
生成したい架空のポケモン名とか特徴を与えて生成できるようになれば・・・ その話はこれ Finetune Stable Diffusionかな。少なくとも 30GB の GPU メモリが必要( highly recommended )らしい。
Liked some of this entry? Buy me a coffee, please.