Haskell xlsx を使ってエクセルデータの読み書き パート1
xlsx モジュールを使って、エクセルデータの読み書きを試します。
処理内容は、エクセルデータからコンピュータリストを読み取り、所定の条件にマッチした情報のみをエクセルデータとして書き出すことにする。
プロジェクト作成
rw-xlsx プロジェクトを作成します。
$ stack new rw-xlsx
$ cd rw-xlsx
package.yml の dependencies に xlsx, bytestring, lens, containers, text を追記します。
dependencies:
- base >= 4.7 && < 5
- xlsx
- bytestring
- lens
- containers
- text
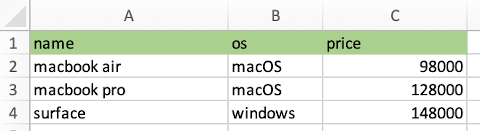
処理対象となるサンプルの computers.xlsx を rw-xlsx/ フォルダに配置しておきます。
セル A1 の内容を読み取る
まずエクセルデータの読み込みをします。
読み込むためのコードサンプルが ここ にあります。
bs <- L.readFile "computers.xlsx" して toXlsx bs すれば Xlsx型の値 が得られます。
その値を使って (1,1) のセルの値を得るには次のようにします。
app/Main.hs を以下のように編集:
{-# LANGUAGE OverloadedStrings #-}
module Main where
--import Lib
import Codec.Xlsx
import Control.Lens
import qualified Data.Text as T
import qualified Data.ByteString.Lazy as L
type SheetName = T.Text
type RowAndCol = (Int,Int)
toMaybeCellValue :: Xlsx -> SheetName -> RowAndCol -> Maybe CellValue
toMaybeCellValue xlsx sheetName rowAndCol = xlsx ^? ixSheet sheetName . ixCell rowAndCol . cellValue . _Just
toMaybeCellValueA1 :: L.ByteString -> Maybe CellValue
toMaybeCellValueA1 bs = toMaybeCellValue (toXlsx bs) "Sheet1" (1,1)
main :: IO ()
main = (L.readFile "computers.xlsx") >>= (\bs -> return (toMaybeCellValueA1 bs)) >>= (\mcv -> putStrLn $ show mcv)
pure か return か、という話で、以前のエントリーでは とりあえず return でも pure でも構わないところは pure を(個人的な方針として)使うと書いていたのですが、(Applicativeではなく)Monad を使っているところでは return を使うのが haskell のお作法との記述を 入門Haskellプログラミング P.386 でみかけたので return を使います。
^? という謎なオペレータが出現しています。 これは Lens に所属するものです。 Lens のさまざまなオペレータは こちら を参照のこと。
^? の型シグネチャ宣言は:
(^?) :: s -> Getting (First a) s a -> Maybe a
🤔 🤔 🤔
まあ、シグネチャはともかく、次のように Xlsx と SheetName と (row,col) を適用すれば Maybe CellValue を得られます。
toMaybeCellValue :: Xlsx -> SheetName -> RowAndCol -> Maybe CellValue
toMaybeCellValue xlsx sheetName rowAndCol = xlsx ^? ixSheet sheetName . ixCell rowAndCol . cellValue . _Just
それでは、実行。
$ stack run
Just (CellText "name")
うまくいきました。
データを読み取る
セル A1 だけでなく computers.xlsx の A1..C4 に存在しているデータをすべて取得してみます。
次のようなインタフェースを考えます。
type Row = [Maybe CellValue]
type RowIndex = Int
toRow :: Xlsx -> SheetName -> RowIndex -> Row
toRow 関数で Xlsx, SheetName, RowIndex から Row を生成します。
toRow 関数の実装:
toRow xlsx sheetName rowIndex = map (\rowAndCol -> toMaybeCellValue xlsx sheetName rowAndCol) rowAndCols
where rowAndCols = [(rowIndex,1),(rowIndex,2),(rowIndex,3)]
toRow を使うように、main を書きかえます。
main = (L.readFile "computers.xlsx")
>>= (\bs -> return (toXlsx bs))
>>= (\xlsx -> return (toRow xlsx "Sheet1" 1))
>>= (\row1 -> putStrLn $ show row1)
stack run して確認:
$ stack run
[Just (CellText "name"),Just (CellText "os"),Just (CellText "price")]
1行目が取得できています!
インデックスの指定が 1-index 方式である点に注意。
ヘッダ行だけでなくボディ行も取得してみましょう。
関数 toRow は、指定したひとつの行のみを取得します。 これを使って 複数行を一度に取得できる toRows' という関数をつくります。
ほんとうは普通に toRows という関数名にしたいのですが、 toRows という関数は既に Codec.Xlsx.toRows にすでに存在しているため、ここでは toRows' という関数名にしています。
toRows' :: Xlsx -> SheetName -> [RowIndex] -> [Row]
toRows' xlsx sheetName rowIndexs = map (\rowIndex -> toRowXlsxSheetName rowIndex) rowIndexs
where toRowXlsxSheetName = toRow xlsx sheetName
main も toRows' を使用し、2,3,4 行目を取得するように修正します。
main = (L.readFile "computers.xlsx")
>>= (\bs -> return (toXlsx bs))
>>= (\xlsx -> return (toRows' xlsx "Sheet1" [2,3,4]))
>>= (\row1 -> putStrLn $ show row1)
確認:
> stack run
[[Just (CellText "macbook air"),Just (CellText "macOS"),Just (CellDouble 98000.0)],[Just (CellText "macbook pro"),Just (CellText "macOS"),Just (CellDouble 128000.0)],[Just (CellText "surface"),Just (CellText "windows"),Just (CellDouble 148000.0)]]
うまくボディ行が全部取得できました。
ここまでのコードのまとめ: app/Main.hs
{-# LANGUAGE OverloadedStrings #-}
module Main where
--import Lib
import Codec.Xlsx
import Control.Lens
import qualified Data.Text as T
import qualified Data.ByteString.Lazy as L
type SheetName = T.Text
type RowAndCol = (Int,Int)
toMaybeCellValue :: Xlsx -> SheetName -> RowAndCol -> Maybe CellValue
toMaybeCellValue xlsx sheetName rowAndCol = xlsx ^? ixSheet sheetName . ixCell rowAndCol . cellValue . _Just
type Row = [Maybe CellValue]
type RowIndex = Int
toRow :: Xlsx -> SheetName -> RowIndex -> Row
toRow xlsx sheetName rowIndex = map (\rowAndCol -> toMaybeCellValue xlsx sheetName rowAndCol) rowAndCols
where rowAndCols = [(rowIndex,1),(rowIndex,2),(rowIndex,3)]
toRows' :: Xlsx -> SheetName -> [RowIndex] -> [Row]
toRows' xlsx sheetName rowIndexs = map (\rowIndex -> toRowXlsxSheetName rowIndex) rowIndexs
where toRowXlsxSheetName = toRow xlsx sheetName
main :: IO ()
main = (L.readFile "computers.xlsx")
>>= (\bs -> return (toXlsx bs))
>>= (\xlsx -> return (toRows' xlsx "Sheet1" [2,3,4]))
>>= (\row1 -> putStrLn $ show row1)
セルに値が入っている範囲を調べる
今題材にしている computers.xlsx は小さなスプレッドシートなので、データが A1..C4 に範囲に存在しているのはすぐわかります。 しかし、いつもこの範囲のエクセルデータを処理するとは限りません。 そこで、どの範囲に値が存在しているかを調べる関数 toRowCount, toColCount を用意して、 値の存在する範囲の異なる任意のスプレッドシートに対処可能にします。
ただし、A1 から連続してデータが入っていることが前提とはなりますが。
インタフェースは簡単ですね。
toRowCount :: Xlsx -> SheetName -> Int
toColCount :: Xlsx -> SheetName -> Int
実装はどうしましょうか。 1から順番に調べて、もし Maybe CellValue の値が Nothing になったら、そこが終端と判定しましょう。
toRowCount' :: Xlsx -> SheetName -> Int -> Int
toRowCount' xlsx sheetName rowIndex
| isNothing = rowIndex-1
| otherwise = toRowCount' xlsx sheetName (rowIndex+1)
where isNothing = if (toMaybeCellValue xlsx sheetName (rowIndex, 1)) == Nothing then True else False
toRowCount :: Xlsx -> SheetName -> Int
toRowCount xlsx sheetName = toRowCount' xlsx sheetName 1
toRowCount' という補助関数を用意しました。 この関数は 1列目を順に A1, B1, C1 ... と調べて、 Nothing になったら再帰を終了して rowIndex-1 した値を返す。
toColCount も同様に:
toColCount' :: Xlsx -> SheetName -> Int -> Int
toColCount' xlsx sheetName colIndex
| isNothing = colIndex-1
| otherwise = toColCount' xlsx sheetName (colIndex+1)
where isNothing = if (toMaybeCellValue xlsx sheetName (1, colIndex)) == Nothing then True else False
toColCount :: Xlsx -> SheetName -> Int
toColCount xlsx sheetName = toColCount' xlsx sheetName 1
main を修正して、この関数が意図通り 4行 x 3列 のデータと判定できるか確認します。
main = (L.readFile "computers.xlsx")
>>= (\bs -> return (toXlsx bs))
>>= (\xlsx -> return ((toRowCount xlsx "Sheet1"),(toColCount xlsx "Sheet1")))
>>= (\rowAndCol -> putStrLn $ show rowAndCol)
実行して確認:
$ stack run
(4,3)
意図通り計算できました。
この辺で、いい加減 main を do 表記に書きかえておきます。
main = do
bs <- L.readFile "computers.xlsx"
let
xlsx = toXlsx bs
sheetName = "Sheet1"
rowCount = toRowCount xlsx sheetName
colCount = toColCount xlsx sheetName
putStrLn $ show (rowCount, colCount)
スプレッドシート全体を読み取る
いよいよパート1 読み取り編の仕上げです。
行と列の数がわかったのであとは、読み取るだけです。 関数 toRow が現状では 3列に固定されていますが、これを指定された列数に対応しましょう。
type ColCount = Int
toRow :: Xlsx -> SheetName -> RowIndex -> ColCount -> Row
関数 toRow がどの列まで計算すればよいかわかるように ColCount を加えました。
実装は:
toRow xlsx sheetName rowIndex colCount = map (\rowAndCol -> toMaybeCellValue xlsx sheetName rowAndCol) rowAndCols
where rowAndCols = map (\colIndex -> (rowIndex,colIndex)) $ take colCount [1..]
toRow を使っている toRows' 関数を修正します。
toRows' xlsx sheetName rowIndexs = map (\rowIndex -> toRowXlsxSheetName rowIndex (toColCount xlsx sheetName)) rowIndexs
where toRowXlsxSheetName = toRow xlsx sheetName
toRows' 関数のインタフェース(型シグネチャ宣言)の変更はなし。 toRow 関数を使用している toRowXlsxSheetName の最後に (toColCount xlsx sheetName) を追加して、列数を適用しています。
これですべての関数が準備できたので、実際に使ってみましょう。 main を修正します。
main = do
bs <- L.readFile "computers.xlsx"
let
xlsx = toXlsx bs
sheetName = "Sheet1"
rowCount = toRowCount xlsx sheetName
rowIndexes = take rowCount [1..]
rows = toRows' xlsx sheetName rowIndexes
putStrLn $ show rows
作動を確認します。
$ stack run
[[Just (CellText "name"),Just (CellText "os"),Just (CellText "price")],[Just (CellText "macbook air"),Just (CellText "macOS"),Just (CellDouble 98000.0)],[Just (CellText "macbook pro"),Just (CellText "macOS"),Just (CellDouble 128000.0)],[Just (CellText "surface"),Just (CellText "windows"),Just (CellDouble 148000.0)]]
できました。
まとめ
最後に toRows' 関数をリネームして toRows にします。
toRows という関数名にしたいが Codec.Xlsx.toRows 関数と名前が衝突してしまうから toRows' にしていたのでした。 これは import 宣言部分で hiding を使って Codec.Xlsx.toRows を除外することで解決できます。
import Codec.Xlsx hiding (toRows)
コード全体を確認:
{-# LANGUAGE OverloadedStrings #-}
module Main where
--import Lib
--import Codec.Xlsx
import Codec.Xlsx hiding (toRows)
import Control.Lens
import qualified Data.Text as T
import qualified Data.ByteString.Lazy as L
type SheetName = T.Text
type RowAndCol = (Int,Int)
toMaybeCellValue :: Xlsx -> SheetName -> RowAndCol -> Maybe CellValue
toMaybeCellValue xlsx sheetName rowAndCol = xlsx ^? ixSheet sheetName . ixCell rowAndCol . cellValue . _Just
type Row = [Maybe CellValue]
type RowIndex = Int
type ColCount = Int
toRow :: Xlsx -> SheetName -> RowIndex -> ColCount -> Row
toRow xlsx sheetName rowIndex colCount = map (\rowAndCol -> toMaybeCellValue xlsx sheetName rowAndCol) rowAndCols
where rowAndCols = map (\colIndex -> (rowIndex,colIndex)) $ take colCount [1..]
toRows :: Xlsx -> SheetName -> [RowIndex] -> [Row]
toRows xlsx sheetName rowIndexs = map (\rowIndex -> toRowXlsxSheetName rowIndex (toColCount xlsx sheetName)) rowIndexs
where toRowXlsxSheetName = toRow xlsx sheetName
toRowCount' :: Xlsx -> SheetName -> Int -> Int
toRowCount' xlsx sheetName rowIndex
| isNothing = rowIndex-1
| otherwise = toRowCount' xlsx sheetName (rowIndex+1)
where isNothing = if (toMaybeCellValue xlsx sheetName (rowIndex, 1)) == Nothing then True else False
toRowCount :: Xlsx -> SheetName -> Int
toRowCount xlsx sheetName = toRowCount' xlsx sheetName 1
toColCount' :: Xlsx -> SheetName -> Int -> Int
toColCount' xlsx sheetName colIndex
| isNothing = colIndex-1
| otherwise = toColCount' xlsx sheetName (colIndex+1)
where isNothing = if (toMaybeCellValue xlsx sheetName (1, colIndex)) == Nothing then True else False
toColCount :: Xlsx -> SheetName -> Int
toColCount xlsx sheetName = toColCount' xlsx sheetName 1
main :: IO ()
main = do
bs <- L.readFile "computers.xlsx"
let
xlsx = toXlsx bs
sheetName = "Sheet1"
rowCount = toRowCount xlsx sheetName
rowIndexes = take rowCount [1..]
rows = toRows xlsx sheetName rowIndexes
putStrLn $ show rows
これで読み取り処理は完成です。 エクセルデータの読み書き パート2 に続きます。
補足1
これ:
where isNothing = if (toMaybeCellValue xlsx sheetName (1, colIndex)) == Nothing then True else False
これだけでよいはず:
where isNothing = (toMaybeCellValue xlsx sheetName (1, colIndex)) == Nothing
補足2
列数の計算について。 1行目の列数のみ計算して、それを使用しているが、厳密に言えば、行ごとに列数が異なる可能性はある。 だから、行ごとに列数を確認しながら行取得を行った方がよい気がしますね。
とはいえ、1行目がヘッダー(列見出し)と考えているので、もし行ごとに列数が異なるのであれば、 それはデータに欠損があるということになる。ならば、そこはそこで手当てが必要になる。
あくまでこれはサンプルコードなので、そこまで考えるのはよそう。
Liked some of this entry? Buy me a coffee, please.