pandas, Excel + VBA からの脱出
pandas が Excel + VBA の代わりとして使える可能性があるらしい。 Jupyter Notebook と併用すれば、インタラクティブに処理結果を確認しつつデータ操作できるので、確かにこれは便利。
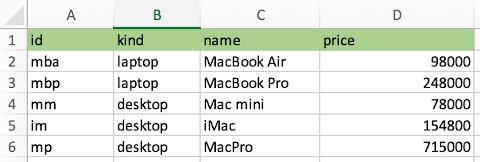
こんなエクセルデータがあったとして、これを pandas で操作していく覚え書き。
事前準備
こんな感じで。適宜 sudo するなりして環境を用意しておく。
apt install python3-pip
pip3 install pandas
pip3 install openpyxl
基本
冒頭のエクセルのファイル ./maclist.xlsx を読み込み:
import pandas as pd
df = pd.read_excel('./maclist.xlsx')
print(df)
python3 main.py などとして実行:
id kind name price
0 mba laptop MacBook Air 98000
1 mbp laptop MacBook Pro 248000
2 mm desktop Mac mini 78000
3 im desktop iMac 154800
4 mp desktop MacPro 715000
name 列だけを抽出:
print(df['name'])
結果:
0 MacBook Air
1 MacBook Pro
2 Mac mini
3 iMac
4 MacPro
price 列に 円 を付加する:
def addYen(priceValue):
return str(priceValue)+ '円'
priceWithYen = df['price'].apply( addYen )
print(priceWithYen)
lambda を使えば、addYen 関数を別途定義する必要はない。 このように:
priceWithYen = df['price'].apply( lambda it: str(it)+ '円' )
print(priceWithYen)
結果:
0 98000円
1 248000円
2 78000円
3 154800円
4 715000円
データフレーム(df) をコピーして df2 をつくり、それの price 列を円付きにする:
df2 = df.copy()
df2['price'] = priceWithYen
print(df2)
結果:
id kind name price
0 mba laptop MacBook Air 98000円
1 mbp laptop MacBook Pro 248000円
2 mm desktop Mac mini 78000円
3 im desktop iMac 154800円
4 mp desktop MacPro 715000円
結果をエクセルファイルに保存:
df2.to_excel('result.xlsx', header=True, index=False)
header は id kind name price の部分です。 index は 最も左の列の 0 1 2 3 4 の部分。 それをオプションで出力するかしないかを指定できます。
これで結果をエクセルファイルとして保存できます。
必要な行だけを取り出す
たとえば、 name が Mac mini の行のみを取り出す:
print(df['name']=='Mac mini')
結果:
0 False
1 False
2 True
3 False
4 False
該当行だけが True になる。 これは期待したのと違う。 そこで、以下のように df[] に入れると:
macMiniRow = df[(df['name']=='Mac mini')]
print(macMiniRow)
結果:
id kind name price
2 mm desktop Mac mini 78000
これで意図通りだが、 df.query を使うともっと直感的に操作できる。 つまり:
macMiniRow = df.query('name=="Mac mini"')
print(macMiniRow)
これで先程と同じ結果が得られる。
もし、MacBook Air と Pro の2つの行を取り出したい場合:
nameList=['MacBook Air', 'MacBook Pro']
df.query('name==@nameList')
結果:
id kind name price
0 mba laptop MacBook Air 98000
1 mbp laptop MacBook Pro 248000
このように 対象文字列のリストを使って該当行を抽出できる。
さらに たとえば、価格が10万円以下の行だけにする:
dfLessThan100k = df.query('price<100000')
print(dfLessThan100k)
id kind name price
0 mba laptop MacBook Air 98000
2 mm desktop Mac mini 78000
さらに、 kind が desktop で 20万円以下の行だけを抽出する:
dfDesktopAndLessThan200k = df.query('kind="desktop" and price<200000')
print(dfDesktopAndLessThan200k)
結果:
id kind name price
2 mm desktop Mac mini 78000
3 im desktop iMac 154800
さらに、いわゆる LIKE 的な処理はできるのか? ということで MacBook という文字が含まれている行だけ抽出するには? df.query('name like "MacBook") で取り出せるのかと思ったがうまくいかなかった。
その代わりに str.contains を使う:
macbookLikeRows = df.query('name.str.contains("MacBook")')
print(macbookLikeRows)
結果:
id kind name price
0 mba laptop MacBook Air 98000
1 mbp laptop MacBook Pro 248000
必要な列だけを取り出す
たとえば、name と price だけの列を持つ DataFrame をつくろうとする:
df['name', 'price']
これはエラーになります。 KeyError: ('name', 'price') と言われる。
それならば、こうしてみる:
nameAndPrice = df[['name', 'price']]
print(nameAndPrice)
結果:
name price
0 MacBook Air 98000
1 MacBook Pro 248000
2 Mac mini 78000
3 iMac 154800
4 MacPro 715000
意図通りになりました。
これはどうなるか?
print(df['name'])
結果:
0 MacBook Air
1 MacBook Pro
2 Mac mini
3 iMac
4 MacPro
エラーは出ません。意図した結果です。
df['name'] を type して型を調べます.
print( type(df['name']) )
→ <class 'pandas.core.series.Series'>
df[['name', 'price']] を type して型を調べます.
print( type(df[['name','price']]) )
→ <class 'pandas.core.frame.DataFrame'>
df に対して 何かした結果の値は pandas.core.frame.DataFrame か pandas.core.series.Series になるようです。 このあたりに注意して操作していく必要がありそうです。
apply の作動を調べる
先ほど、 price 列に存在するすべてのセルの値に対して 円 を付加する処理を書きました:
df['price'].apply( lambda it: str(it) + '円' )
では、 name が MacPro の行に対して すべてのセルの値の末尾に * を追加してみます:
v = df.query('name=="MacPro"').apply( lambda it: str(it) + '*' )
print(v)
結果:
id 4 mp\nName: id, dtype: object*
kind 4 desktop\nName: kind, dtype: object*
name 4 MacPro\nName: name, dtype: object*
price 4 715000\nName: price, dtype: int64*
なんだかよくわからない結果になりました。意図通りではないです。
では、squeeze() を使います。
v = df.query('name=="MacPro"').squeeze().apply( lambda it: str(it) + '*' )
print(v)
結果:
id mp*
kind desktop*
name MacPro*
price 715000*
意図通りになりました。
何がどうなっているのか? type して調べてみます。
t0 = type( df.query('name=="MacPro"') )
t1 = type( df.query('name=="MacPro"').squeeze() )
print(t0)
print(t1)
結果:
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.series.Series'>
df.query('name=="MacPro"') は DataFrame で それを squeeze() すると Series になると。
squeeze() は次元を削減する機能のようです。
つまり apply で lambda it したときの it に何が入っているかの問題です。 Series に対して apply すれば lambda it の it には 各セルの値 が入ります。 DataFrame に対して apply すれば lambda it の it には Series が入ることになる。
最初の意図した結果にならなかったものは Series を str で文字列にしたものの末尾に * を入れたということでしょう。
description 列を作り出す
apply の作動がなんとなくわかったところで、description 列を追加することを考えます。 つまり、name 列と price 列の値を足し合わせてその行を説明するそれっぽい文字列を作り出すことを考えます。
そのためには df に対して apply して 各行を取り出しつつ name 列 price 列のセルの値を使って文字列を作り出します。 df.appy したときに lambda it で it に入るのは Series です。 この Series には 一行分が入っているので、それを it['name'] とか it['price'] して name, price のセル値を取り出します。
nameAndPriceColumn = df.apply( lambda it: it['name'] + str(it['price']) )
はい、エラーになりました。 これに axis=1 オプションを追加します。
nameAndPriceColumn = df.apply( lambda it: it['name'] + str(it['price']) , axis=1 )
print(nameAndPriceColumn)
結果:
0 MacBook Air98000
1 MacBook Pro248000
2 Mac mini78000
3 iMac154800
4 MacPro715000
意図通りになりました。
これ何が起きたかというと、df (DataFrame) は 2次元のデータなので、 apply で走査するときに、上から下に行単位で走査するか、左から右に列単位で走査するか、 の2通りの処理方法がありえます。 デフォルトは列単位で走査していく axis=0 になっている。 したがって、 axis=1 オプションがない場合デフォルトで axis=0 が指定されたことになり、 列単位で走査していく結果、 it['name'] とか指定しても値が取り出せない。 axis=1 を指定することで、行単位での走査になるので、 it['name'] や it['price'] が有効になる、ということだと思います。
これはあくまで動かしてみてそのように理解しただけです。本当かどうかはわかりません。鵜呑みにしないで pandas のドキュメントなり読むようにしてください。
では、リファクタリングしましょう。
nameAndPriceColumn = df.apply( lambda it: '{name} <{price}円>'.format(name=it['name'], price=it['price']) , axis=1 )
print(nameAndPriceColumn)
結果:
0 MacBook Air <98000円>
1 MacBook Pro <248000円>
2 Mac mini <78000円>
3 iMac <154800円>
4 MacPro <715000円>
それでは仕上げに、これを description 列としてもとの df に追加します:
df['description'] = df.apply( lambda it: '{name} <{price}円>'.format(name=it['name'], price=it['price']) , axis=1 )
print(df)
結果:
id kind name price description
0 mba laptop MacBook Air 98000 MacBook Air <98000円>
1 mbp laptop MacBook Pro 248000 MacBook Pro <248000円>
2 mm desktop Mac mini 78000 Mac mini <78000円>
3 im desktop iMac 154800 iMac <154800円>
4 mp desktop MacPro 715000 MacPro <715000円>
新たに DataFrame を生成する
ここまでは、dataFrame インスタンスを直接書き換える形で値を更新していましたが、これはちょっと気持ち悪いです。 もとの dataFrame はイミュータブルとして扱い、変更したければ、コピーして新たな dataFrame を作った方が精神衛生上良い。 ということで、これを先程の description 列を作り出す例で試します。
DataFrame インスタンを作り出す方法は幾通りかありますが、 df.DataFrame に ディクショナリのリストを渡す方法がもっとも簡単に思えたのでこれを使います。 せっかくなので、新しく生成する DataFrame は id, kind, description の列だけを持つようにしましょう。
rowList = []
for _, row0 in df.iterrows():
row1 = {}
row1['id'] = row0['id']
row1['kind'] = row0['kind']
row1['description'] = '{name} <{price} 円>'.format( name=row0['name'], price=row0['price'] )
rowList.append(row1)
df3 = pd.DataFrame(rowList)
print(df3)
行ごとにループして、行の Series を row0 に取得。 あとはその行ごとの新たなディクショナリを生成して、rowListに追加。 最後に、新たな DataFrame インスタンスを生成。
結果:
id description
0 mba MacBook Air <98000 円>
1 mbp MacBook Pro <248000 円>
2 mm Mac mini <78000 円>
3 im iMac <154800 円>
4 mp MacPro <715000 円>
まとめ
ごく基本のスプレッドシートデータ操作を把握できました。 ここまでは pandas のお作法さえわかれば、Python の知識ほぼなしで処理できる範囲です。 さらにここから数値や文字列操作など複雑な処理をやろうとすると、Pythonのコードを書いていくことになります。 それが Python で書けて便利!なのか、エクセル関数になれているからそちらのが楽なのか。
そのあたりのこととは無関係に Pandas の MS Excel に対するアドバンテージは速いことです。 データ量が多くても一瞬で処理が済むのはほんとうに良い。
Liked some of this entry? Buy me a coffee, please.