Word2Vec, 単語ベクトルを2次元でマッピング
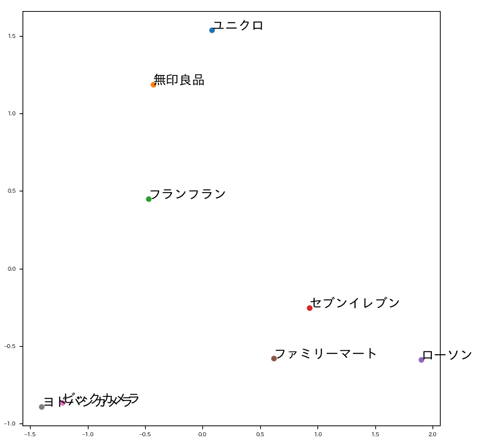
「Javaで学ぶ自然言語処理と機械学習」という本で紹介されていた Wikipedia でトレーニング済みの単語分散表現データが便利。 このデータの活用例として日本のブランドのマップを作成してみた。
ちなみに、この手の 単語ベクトルを2次元まで圧縮して2D表示的な話は Qitta をはじめあちこちで散々出ているネタですが、自分用メモおよび Ubuntu 18.04 の人および Java で機械学習やりたい人の参考になればと思いシェアします。 もっとも肝心の 2D マップ変換は 普通に Python です。
Step 1
Wikipedia Entity Vectors で配布されている Wikipedia Entity Vectors release data の jawiki.word_vectors.100d.txt.gz を入手。
Step 2
この jawiki.word_vectors.100d.txt.gz などのデータを読むためのライブラリ(手前味噌ですが)を以下から入手して ローカル maven レポジトリに入れる。
git clone して ./gradlew publishMavenPublicationToMavenLocal するだけです。
Step 3
かなり恣意的ではあるが以下のブランドを試す。
- ユニクロ, 無印良品, フランフラン, セブンイレブン, ローソン, ファミリーマート, ビックカメラ, ヨドバシカメラ
結果は result.json へ保存される。
createJson.groovy
@GrabResolver(name='local', root='file://~/.m2/repository')
@Grab(group='jp.osima.app.ml', module='wevr', version='0.1.0-SNAPSHOT')
import groovy.json.*
import jp.osima.app.ml.wevr.WordDictionaryFactory
def gzippedVectorsTxtFile = new File('jawiki.word_vectors.100d.txt.gz')
def cacheFile = new File('cache.mdb')
def obj = [:]
obj.list = []
def wordDictionary = WordDictionaryFactory.createWordDictionary(gzippedVectorsTxtFile, cacheFile)
if( wordDictionary!=null ){
def words = 'ユニクロ,無印良品,フランフラン,セブンイレブン,ローソン,ファミリーマート,ビックカメラ,ヨドバシカメラ'.split(/,/)
words.each { word->
def vecWord = wordDictionary.get( word.trim() )
if( vecWord!=null ){
obj.list << [
word: vecWord.word,
vector: vecWord.vector]
}
else {
println "${word.trim()} not found"
}
}
}
new File('result.json').text = new JsonBuilder( obj ).toString()
Step 4
出力した result.json を読み込み 2D マップを出力する。 (コードは python3 用)
createMap.py
import matplotlib.pyplot as plot
from sklearn.decomposition import PCA
import json
plot.rcParams["figure.figsize"] = [8, 8]
plot.rcParams['font.size'] = 6
jsonFile = open('result.json', 'r')
jsonObj = json.load(jsonFile)
data = []
labels = []
length = len(jsonObj['list'])
for index in range(0, length):
item = jsonObj['list'][index]
data.append( item['vector'] )
labels.append( item['word'] )
pca = PCA(n_components=2)
pca.fit(data)
data_pca = pca.transform(data)
length = len(data_pca)
for index in range(0, length):
x = data_pca[index][0]
y = data_pca[index][1]
plot.plot(x, y, ms=5.0, zorder=2, marker="o")
label = labels[index]
plot.annotate(label, (x, y), size=14)
plot.savefig('word-map.png')
結果 word-map.png に出力される。 以上です。
補足) 日本語フォントの文字化け解消設定
Matplotlib はインストールした状態では 日本語フォントが設定されていないらしい。 結構面倒だったので、Ubuntu 18.04 での日本語フォント設定をメモしておきます。
日本語フォントを入れる
sudo apt install fonts-ipaexfont
以下のコードを実行して、システム全体の設定ファイルの所在とか、自分用の設定ファイルの所在を把握しておく。
check.py
import matplotlib
print(matplotlib.matplotlib_fname())
print(matplotlib.get_configdir())
自分用設定ファイルは ~/.config/matplotlib/matplotlibrc だったので・・・これの以下の部分を変更。
font.family : sans-serif
font.sans-serif : IPAexGothic, DejaVu Sans, .... 以下略
そして、フォントキャッシュがあれば削除する(重要)
rm -rf ~/.cache/matplotlib/fontlist-v300.json
これで日本語出力できるようになりました。
フォントキャッシュを消さないと設定が反映されないので、この部分でかなり時間をとられました。 ドキュメント読めばたぶん書いてあるんでしょうけど。