一次関数の傾きと切片を人工ニューロンを使って推測する
「初めての TensorFlow.js」の8章にニューロン一個を使って一次関数を導く例が出ていた。
任意の一次関数の x,y のセットを機械学習させることで、 y = a*x +b の a(傾き)と b(切片)を機械的に見つけることができる、という話。 そこで、これ相当の機能を自前のコードで実装することを試みた。
TensorFlow.js ならこれだけの話(コードは抜粋)。
const model = tf.sequential();
model.add(
tf.layers.dense({
inputShape: 1,
units: 1
})
);
model.compile({
optimizer: "sgd",
loss: "meanSquaredError"
});
y = 2x +1 を機械学習する、という例を考える
ニューロン(重みw とバイアスb を持つとする)に x を与えると y を計算できるようにしたい。
まずニューロンに与える x と y のリストをつくります。(コードは javascript)
const xs = [1,2,3,4,5];
const ys = [3,5,7,9,11];
x=1 のとき y=3, x=2 のとき y=5 という具合いです。
重みw とバイアスb は学習により獲得するので、初期値は適当な値として、以下をセット。
const w = 0.1;
const b = 0.2;
ニューロンとして振る舞う関数を定義.
const neuron = (w,b)=>{
return (x)=>{ return w * x + b; };
};
一回目の学習を行います。
const neuronFunc = neuron(w,b);
const predY = neuronFunc(xs[0]);
console.log(predY);
実行すると、predY(推測した値Y)は 0.30000000000000004 になりました。 期待する値は 3 なので全然違う値ですが、適当に設定した w, b なので正解が出ないのは当然です。
この現在の推測値と正解との差の計算は 定番の MSE にします。 といっても今は一つだけしかないので、単に差の自乗ということになります。
const error = Math.pow((predY-ys[0]), 2);
この error が 0 になるように学習していきたい。つまり、そうなるように w と b の値を調整したい。 調整といっても結局減らすか増やすかするだけの操作しかできないので、どれだけ増やす or 減らすかという問題。
では、 error が 0 になる(近づく)ように変更するにはどうすればいいのかを考えます。
ここまでの計算を整理すると:
- predY = w*xs[0] + b
- error = (predY - ys[0])**2
になります。つまりこれを一つの式にまとめると:
- error = (w*xs[0] + b - ys[0])**2
になります。
今、xs[0], b, ys[0] は固定(現在の値のままで)して、w をどう変化させたらエラーが0に近づくか考えたい。 そこで xs[0], b, ys[0] に現在の値を代入して式を書き直せば:
- error = (w*1 + 0.2 - 3)**2 つまり error = (w - 2.8)**2
さらに、これを展開して:
- error = w**2 - 5.6*w + 7.84
になります。
結局のところ、w 値を変化させたとき error がどうなるか知りたい! ということ。 なので、w と error の関係を把握したい。 それは式で表せば error = w**2 - 5.6*w + 7.84 なので、これを w を X軸に error をY軸にしたグラフをつくります。
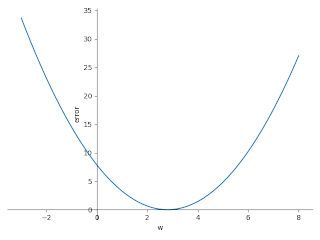
w と error の関係を表した二次関数の式( error = (w - 2.8)**2 )から明らかですが、w=2.8 で error が 0 になります。 そして、グラフを見ればわかるように、 w が 2.8 より小さい場合は w の値を増やす、 w が 2.8 より大きい場合は、 w の値を減らす、ことで、 error が 0 に近づくことになります。 (もっとも、これはあくまで 現在の w 以外の値を固定した状況においては、という話。)
つまり、簡単に言えば、 error = w**2 - 5.6*w + 7.84 を微分した(つまりその w 値における接線の傾きの)値の方向に w を調整すればよい。 方向というのは、つまり、接線の傾きがマイナスの場合は w を増やす方向に、プラスの場合は w を減らす方向に調整する、ということ。 そうすれば、 error が 0 に近づくように w 値を更新できることになる。
- ∂error/∂w = 2*w - 5.6
次回の w 値(nextW) の計算式:
- nextW = w - (2*w - 5.6)*α
α はここでは 0.01 とする。これは error を 0 にゆっくり近づけるための係数。
現在の w値は 0.1 なので、この式に当てはめると:
- nextW = 0.1 - (2*0.1 - 5.6)*0.01
- nextW = 0.1 - (-0.054)
- nextW = 0.1 + 0.054
- nextW = 0.154
ということなります。 現在 w 値は 2.8 より小さい値なので、これを少し増やすことになります。(errorが 0 に近づく方に値が移動している。)
以上で、w の更新の計算ができました。
コードで確かめます。
const neuron = (w,b)=>{
return (x)=>{ return w * x + b; };
};
// error = ((w*x + b) - y)**2
const toError = (w,b,x,y)=> {
return Math.pow( neuron(w,b)(x)-y, 2);
};
// ∂error/∂w
const diffErrorW = (w,b,x,y)=>{
const delta = 0.00001;
return (toError(w+delta, b,x,y) - toError(w-delta, b,x,y))/(delta*2);
};
const xs = [1,2,3,4,5];
const ys = [3,5,7,9,11];
const α = 0.01;
const w = 0.1;
const b = 0.2;
const nextW = w - diffErrorW(w,b,xs[0],ys[0])*α;
console.log(nextW);
実行:
0.15399999999911032
これでようやく w の更新(次回の値)をきめることができました。
次は b の更新です。 今度は w を固定して b が変化したときに error 値がどう変化するか、つまりは、 ∂error/∂b を求めればよいことになります。
- predY = w*xs[0] + b
- error = (predY - ys[0])**2
これを一つの式にまとめる:
- error = (w*xs[0] + b - ys[0])**2
ここまでは先ほどと同じ。 そして、今度は w, xs[0], ys[0] を固定するので:
- error = (0.1*1 + b - 3)**2
になります。 これを整理した二次関数:
- error = (b-2.9)**2
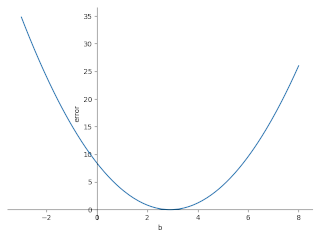
微分すると:
- ∂error/∂b = 2*b - 5.8
bの更新:
- nextB = b - (2*b - 5.8)*α
b の現在値は 0.2 なので:
- nextB = 0.2 - (2*0.2 - 5.8)*0.01
- nextB = 0.2 - (0.4 - 5.8)*0.01
- nextB = 0.2 - (-5.4)*0.01
- nextB - 0.254
になります。
以上からこれをコードにすると:
// ∂error/∂b
const diffErrorB = (w,b,x,y)=>{
const delta = 0.00001;
return (toError(w, b+delta ,x,y) - toError(w, b-delta ,x,y))/(delta*2);
};
const nextB = b - diffErrorB(w,b,xs[0],ys[0])*α;
console.log(nextB);
実行する:
0.2539999999991103
0.2 は 2.9 より小さい値だったので、プラス方向へ更新されたので、これでよさそう。 (現在の状況では b が 2.9 のときに error が 0 になるので。)
一度ここまでのコードを確認しましょう。
const neuron = (w,b)=>{
return (x)=>{ return w * x + b; };
};
// error = ((w*x + b) - y)**2
const toError = (w,b,x,y)=> {
return Math.pow( neuron(w,b)(x)-y, 2);
};
// ∂error/∂w
const diffErrorW = (w,b,x,y)=>{
const delta = 0.00001;
return (toError(w+delta, b,x,y) - toError(w-delta, b,x,y))/(delta*2);
};
// ∂error/∂b
const diffErrorB = (w,b,x,y)=>{
const delta = 0.00001;
return (toError(w, b+delta ,x,y) - toError(w, b-delta ,x,y))/(delta*2);
};
const xs = [1,2,3,4,5];
const ys = [3,5,7,9,11];
const α = 0.01;
const w = 0.1;
const b = 0.2;
const nextW = w - diffErrorW(w,b,xs[0],ys[0])*α;
console.log(nextW);
const nextB = b - diffErrorB(w,b,xs[0],ys[0])*α;
console.log(nextB);
ここまでで一度の学習と weight, bias 更新ができるようになりました。
それでは、 nextW, nextB と xs[1], ys[1] を使って次の学習(wとbの更新)を行うコードを書くこともできるのですが、 これ以後は、同じ繰り返しになるので、このままでは冗長すぎます。コードを手直しします。
再帰コードを書くために underscore を導入します。
const _ = require('underscore');
// 途中省略
const recur = (w, b, xyList)=>{
if( _.size(xyList)==0 ){
return { weight: w, bias: b };
} else {
const α = 0.01;
const x = _.head(xyList)[0];
const y = _.head(xyList)[1];
const nextW = w - diffErrorW(w,b,x,y)*α;
const nextB = b - diffErrorB(w,b,x,y)*α;
return recur(nextW, nextB, _.tail(xyList));
}
};
const xs = [1,2,3,4,5];
const ys = [3,5,7,9,11];
const w = 0.1;
const b = 0.2;
const wAndB = recur(w,b, _.zip(xs,ys));
console.log(`weight=${wAndB.weight}, bias=${wAndB.bias}`);
実行してみます。
weight=1.6126758416035278, bias=0.6677280611180556
目標とする関数は y = 2x +1 なので、 初期値から見れば weight が 2, bias が 1 に近づいてはいますが、 ひとめぐり訓練しただけでは、正解には到達していません。
訓練を300回繰り返してみます。
let currentW = w;
let currentB = b;
_.each(_.range(300), (epoch)=>{
const wAndB = recur(currentW,currentB, _.zip(xs,ys));
currentW = wAndB.weight;
currentB = wAndB.bias;
console.log(`- ${(epoch+1)} epoch: weight=${wAndB.weight}, bias=${wAndB.bias}`);
});
実行してみます。
- 298 epoch: weight=2.0002207815643493, bias=0.9990639186900169
- 299 epoch: weight=2.0002168329119057, bias=0.9990806603947111
- 300 epoch: weight=2.0002129548806487, bias=0.9990971026759765
うまく weight=2 と bias=1 に限りなく近づいています。
これ逆に初期値を w=10, b=20 に変更して実行してみます。
- 298 epoch: weight=1.983195136548321, bias=1.071250145546752
- 299 epoch: weight=1.9834956895647506, bias=1.0699758450309222
- 300 epoch: weight=1.9837908672256481, bias=1.0687243352307065
やはり、うまく狙った値に近づいています。
では、今度は、 y = 5x - 10 を推測できるか(機械学習できるか)調べてみます。
トレーニングするための値 xs, ys を変更します。
/*
// y = 2x +1
const xs = [1,2,3,4,5];
const ys = [3,5,7,9,11];
*/
// y = 5x -10
const xs = [1, 2, 3, 4, 5];
const ys = [-5,0, 5,10,15];
これで実行してみます。
- 298 epoch: weight=4.971089412921103, bias=-9.877423369542685
- 299 epoch: weight=4.971606475388047, bias=-9.879615638235153
- 300 epoch: weight=4.972114290253273, bias=-9.881768698458586
うまく、5 と -10 に近い値になりました。
まとめ
最終的に完成したコードを載せておきます。
const _ = require('underscore');
const neuron = (w,b)=>{
return (x)=>{ return w * x + b; };
};
// error = ((w*x + b) - y)**2
const toError = (w,b,x,y)=> {
return Math.pow( neuron(w,b)(x)-y, 2);
};
// ∂error/∂w
const diffErrorW = (w,b,x,y)=>{
const delta = 0.00001;
return (toError(w+delta, b,x,y) - toError(w-delta, b,x,y))/(delta*2);
};
// ∂error/∂b
const diffErrorB = (w,b,x,y)=>{
const delta = 0.00001;
return (toError(w, b+delta ,x,y) - toError(w, b-delta ,x,y))/(delta*2);
};
const recur = (w, b, xyList)=>{
if( _.size(xyList)==0 ){
return { weight: w, bias: b };
} else {
const α = 0.01;
const x = _.head(xyList)[0];
const y = _.head(xyList)[1];
const nextW = w - diffErrorW(w,b,x,y)*α;
const nextB = b - diffErrorB(w,b,x,y)*α;
return recur(nextW, nextB, _.tail(xyList));
}
};
/*
// y = 2x +1
const xs = [1,2,3,4,5];
const ys = [3,5,7,9,11];
*/
// y = 5x -10
const xs = [1, 2, 3, 4, 5];
const ys = [-5,0, 5,10,15];
const w = 10;
const b = 20;
let currentW = w;
let currentB = b;
_.each(_.range(300), (epoch)=>{
const wAndB = recur(currentW,currentB, _.zip(xs,ys));
currentW = wAndB.weight;
currentB = wAndB.bias;
console.log(`- ${(epoch+1)} epoch: weight=${wAndB.weight}, bias=${wAndB.bias}`);
});
一次関数を推測するニューロンの場合は、このようにニューロン1個で済むのと、ニューロンに活性化関数が必要ないので、 まだよいが、二次関数の推測となると活性化関数が必須らしい、しかもニューロンもたくさん必要になる。もう無理。
追伸 kotlin に移植
JavaScript のコードを kotlin に移植しました。 型が明示されているのでコーディングしている最中はわかり易くよき。 その反面、あとでコードを読もうとするとごちゃごちゃ感がある。
main.kt
val neuron: (Float,Float)-> (Float)->Float = { w,b->
{ x-> w * x + b }
}
// error = ((w*x + b) - y)**2
val toError: (Float, Float, Float, Float)->Float = {w,b,x,y->
Math.pow( (neuron(w,b)(x) - y).toDouble(), 2.toDouble()).toFloat()
}
// ∂error/∂w
val diffErrorW: (Float, Float, Float, Float)->Float = {w,b,x,y->
val delta = 0.00001f
((toError(w+delta, b,x,y) - toError(w-delta, b,x,y))/(delta*2f)).toFloat()
}
// ∂error/∂b
val diffErrorB: (Float, Float, Float, Float)->Float = {w,b,x,y->
val delta = 0.00001f
((toError(w, b+delta ,x,y) - toError(w, b-delta ,x,y))/(delta*2f)).toFloat()
}
val head: (List<Pair<Float,Float>>) -> Pair<Float,Float> = { xyList->
xyList.first()
}
val tail: (List<Pair<Float,Float>>) -> List<Pair<Float,Float>> = { xyList->
xyList.drop(1)
}
tailrec fun recur(w: Float, b: Float, xyList: List<Pair<Float,Float>>): Pair<Float,Float> {
if( xyList.size==0 ){
return Pair(w,b)
} else {
val α = 0.01f
val x = head(xyList).first
val y = head(xyList).second
val nextW = w - diffErrorW(w,b,x,y)*α
val nextB = b - diffErrorB(w,b,x,y)*α
return recur(nextW, nextB, tail(xyList))
}
}
fun main(){
val xs = listOf(1, 2, 3, 4, 5).map { it.toFloat() }
val ys = listOf(-5,0, 5,10,15).map { it.toFloat() }
val w = 10f
val b = 20f
var currentW = w
var currentB = b
0.until(300).forEach { epoch->
val wAndB = recur(currentW, currentB, xs.zip(ys))
currentW = wAndB.first
currentB = wAndB.second
println("- ${(epoch+1)} epoch: weight=${wAndB.first}, bias=${wAndB.second}")
}
}
実行:
$ kotlinc main.kt -include-runtime -d main.jar
$ java -jar main.jar
...
- 298 epoch: weight=4.966011, bias=-9.856124
- 299 epoch: weight=4.966585, bias=-9.858573
- 300 epoch: weight=4.9671607, bias=-9.860983
Liked some of this entry? Buy me a coffee, please.